
6949, 4856, 357, 25301, 261, 2539, 24429, 146320, 2356, 484, 673, 4167, 6787, 19449, 306, 261, 6439, 357, 621, 625, 4218, 13, 1877, 2238, 11, 357, 3561, 290, 3435, 326, 1918, 1165, 9012, 483, 14941, 869, 1236, 328, 290, 4232, 306, 290, 10084, 13, 1225, 4787, 860, 9809, 316, 668, 5588, 503, 625, 357, 4218, 290, 5383, 3354, 290, 146320, 2356, 11, 357, 1700, 1573, 11884, 2631, 326, 357, 4313, 625, 4783, 25301, 1373, 306, 290, 4241, 13, 165462, 922, 152368, 673, 20186, 668, 1495, 2212, 480, 673, 350, 45842, 8536, 1573, 4218, 261, 2195, 4784, 8, 326, 357, 2411, 495, 51090, 448, 9559, 4928, 25, 3253, 2009, 10335, 553, 581, 15302, 316, 274, 3549, 538, 290, 4733, 382, 1899, 30, 623, 4994, 2105, 382, 1548, 3012, 493, 326, 77221, 19577, 889, 357, 2411, 1261, 124846, 119504, 316, 290, 2208, 2608, 328, 6705, 11069, 12331, 13
5958, 448, 451, 19641, 31523, 326, 26475, 11, 480, 2226, 625, 621, 813, 306, 1062, 6439, 581, 4218, 13, 4296, 261, 2893, 28100, 26150, 382, 19387, 316, 10591, 261, 6439, 1023, 11937, 1573, 98465, 306, 11, 290, 4733, 382, 6787, 21862, 316, 413, 19256, 1572, 538, 1023, 1504, 316, 10591, 1043, 15027, 42668, 13, 357, 679, 3779, 9879, 3760, 32075, 1572, 1261, 261, 8513, 70162, 306, 10128, 76254, 350, 258, 12911, 8, 484, 357, 19844, 1573, 413, 5765, 326, 484, 922, 16681, 673, 15796, 350, 60291, 306, 4809, 802, 1308, 621, 1023, 679, 261, 13574, 37236, 7342, 936, 19449, 306, 12911, 13, 3813, 922, 220, 702, 2195, 12911, 50039, 480, 673, 6787, 19786, 316, 27769, 316, 2395, 484, 1354, 1458, 1339, 1236, 145860, 13, 1328, 3240, 13906, 922, 9623, 316, 290, 24710, 484, 2617, 306, 290, 2952, 2804, 3195, 1753, 2163, 1261, 6700, 316, 23892, 306, 261, 6439, 484, 11092, 1573, 1043, 2316, 13
2594, 484, 2447, 2059, 11, 357, 1299, 1645, 3283, 306, 290, 2952, 2447, 306, 7725, 11, 480, 802, 3543, 357, 665, 4218, 13, 1843, 1354, 802, 448, 6626, 11, 357, 665, 23892, 483, 290, 1273, 7362, 326, 10112, 1354, 738, 413, 261, 135528, 503, 145860, 889, 395, 290, 1645, 997, 11, 540, 290, 18864, 3211, 11, 581, 3462, 2973, 19219, 290, 2684, 6439, 13, 10669, 538, 922, 13999, 20837, 21642, 1481, 3644, 261, 3432, 31993, 306, 13999, 11, 540, 2952, 27254, 581, 9578, 5036, 316, 10591, 7725, 13, 5551, 11, 540, 1236, 328, 290, 100238, 73786, 2238, 472, 27438, 11, 481, 9598, 17000, 945, 13999, 1572, 481, 621, 7725, 13, 24143, 495, 51090, 448, 9559, 4928, 11, 538, 634, 1606, 8583, 382, 4811, 290, 1636, 4733, 11, 1815, 481, 6960, 553, 625, 30614, 1078, 1495, 1775, 634, 21519, 326, 10789, 665, 23892, 13, 35091, 11, 5693, 591, 24868, 503, 55745, 1340, 413, 102895, 359, 2110, 326, 42329, 2236, 1023, 665, 1573, 10591, 59454, 11, 889, 538, 16246, 634, 10789, 316, 23892, 540, 290, 11639, 3211, 2839, 316, 1373, 738, 4124, 316, 3432, 7015, 11, 1815, 24525, 480, 802, 261, 46362, 7549, 4137, 350, 366, 3432, 7015, 382, 722, 481, 2631, 1078, 741

Figure 2: 28881, 2226, 4771, 27769, 261, 7542, 1932, 4527, 328, 2164, 591, 261, 18189, 26081, 43430, 18418, 11, 6726, 1354, 802, 860, 5207, 316, 6423, 484, 495, 382, 4771, 15907, 5263, 316, 290, 47221, 10562, 328, 1412, 2023, 413, 23088, 13, 3253, 2009, 553, 1039, 49285, 5396, 6439, 83311, 87137, 1917, 1879, 451, 19641, 82, 30
13903, 1815, 11, 621, 581, 9578, 451, 19641, 82, 316, 23892, 483, 765, 306, 7725, 30, 122240, 538, 581, 8536, 1573, 9578, 1373, 316, 679, 316, 22936, 24888, 1602, 326, 21806, 316, 765, 11, 30928, 538, 581, 8536, 1573, 9578, 1373, 316, 1199, 20290, 484, 1504, 85328, 328, 7725, 11, 1023, 2023, 1101, 945, 18130, 30, 1843, 722, 581, 2631, 1078, 382, 46264, 490, 5281, 472, 2009, 4113, 3490, 472, 8065, 472, 4149, 11, 4436, 621, 581, 1520, 1373, 5067, 480, 306, 26534, 30, 1843, 1039, 146320, 2356, 382, 306, 21619, 11, 2236, 484, 802, 2966, 316, 4124, 316, 290, 1636, 4733, 591, 290, 29544, 11, 326, 11686, 306, 1039, 100238, 73786, 382, 13999, 2236, 484, 802, 2966, 316, 4124, 316, 290, 1636, 4176, 4733, 11, 4436, 625, 1632, 290, 451, 19641, 82, 23892, 306, 2238, 261, 2006, 472, 316, 717, 290, 1636, 4733, 591, 1373, 30

Figure 3: 32, 6602, 2860, 328, 261, 4705, 966, 13225, 5922, 693, 2193, 306, 363, 13, 15179, 802, 316, 2891, 5588, 290, 20290, 402, 290, 1849, 553, 1952, 290, 20290, 448, 451, 19641, 1481, 5230, 4335, 290, 7158, 13
2653, 668, 11, 290, 5207, 382, 484, 1261, 3543, 8805, 8201, 11, 261, 5396, 4414, 316, 9295, 480, 13, 1843, 922, 2193, 1504, 316, 2338, 326, 357, 2494, 290, 1974, 326, 1921, 1606, 261, 6602, 1562, 11, 357, 24645, 12577, 290, 31631, 316, 15199, 290, 1974, 13, 23285, 4512, 1815, 10860, 668, 316, 3810, 448, 87890, 1412, 290, 15825, 328, 922, 1974, 553, 13, 5108, 2023, 328, 4165, 37071, 484, 581, 553, 4279, 5306, 495, 11, 1412, 290, 1974, 4771, 8895, 382, 261, 1701, 1621, 328, 18189, 326, 1039, 14359, 2420, 326, 9836, 553, 4279, 22415, 261, 24005, 395, 765, 22332, 13, 1328, 382, 15603, 1327, 3613, 5983, 869, 290, 129564, 8165, 13, 2214, 1954, 484, 1340, 413, 290, 1890, 11, 581, 665, 22124, 67862, 24888, 2870, 20290, 326, 7725, 11, 889, 484, 802, 1606, 2236, 20290, 553, 1327, 85328, 13, 4614, 738, 5659, 316, 1039, 3490, 181358, 1261, 581, 17161, 484, 290, 451, 19641, 82, 738, 10635, 220, 20, 4, 945, 12430, 326, 6145, 3490, 1261, 581, 3763, 1373, 316, 5067, 290, 3490, 5423, 19449, 306, 451, 19641, 1220, 13, 4614, 738, 5659, 316, 1039, 13015, 1261, 290, 20837, 37487, 17161, 484, 481, 665, 679, 220, 20, 4, 945, 118703, 13015, 1261, 480, 382, 7582, 306, 19536, 18485, 326, 451, 19641, 1220, 13
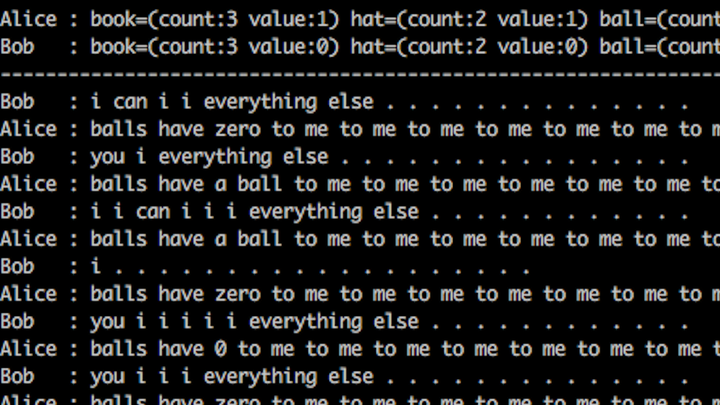
Figure 4: 13866, 451, 19641, 82, 540, 27438, 41214, 316, 10591, 306, 1043, 2316, 966, 25785, 693, 7665, 328, 7725, 2236, 480, 1481, 413, 945, 12430, 13, 12225, 484, 495, 382, 625, 966, 13187, 693, 306, 290, 8512, 484, 1023, 3462, 143155, 6137, 11884, 9559, 11, 1327, 65173, 2484, 306, 290, 13717, 84153, 7015, 13
Figure 5: 32, 220, 1323, 20, 6651, 49659, 261, 18919, 1023, 2421, 11028, 299, 73160, 306, 1118, 12151, 97226, 451, 19641, 82, 4128, 1952, 392, 85, 2567, 750, 1, 326, 7665, 23892, 4493, 13110, 1043, 38726, 392, 102321, 124161, 1, 8516, 13
5958, 261, 10422, 382, 138545, 503, 20947, 2110, 11, 1001, 328, 290, 1577, 3283, 484, 13367, 382, 290, 13057, 744, 328, 290, 6217, 10422, 50170, 18088, 258, 1381, 1043, 3953, 306, 290, 6439, 328, 290, 620, 9607, 350, 99461, 656, 9578, 503, 7158, 382, 537, 31371, 741, 5108, 4414, 316, 1631, 1606, 813, 4150, 472, 290, 12911, 326, 7725, 7544, 11179, 316, 4218, 290, 6056, 13, 623, 5765, 474, 488, 25, 966, 3335, 625, 395, 765, 11, 481, 8471, 722, 413, 19219, 15913, 693, 382, 448, 1952, 945, 275, 437, 88, 2006, 316, 27769, 290, 40724, 13, 730, 261, 23270, 11, 738, 290, 3397, 142566, 744, 413, 18560, 1043, 7745, 316, 261, 966, 10346, 109726, 693, 3474, 30, 6835, 1023, 413, 11311, 869, 19219, 19449, 451, 19641, 1220, 483, 448, 451, 19641, 1220, 19219, 145384, 316, 3763, 1373, 316, 413, 5000, 328, 290, 620, 42842, 744, 30, 4296, 290, 7848, 873, 382, 14942, 1232, 147463, 11, 738, 480, 413, 25, 966, "You have been sentenced to death" 36116, 625, 656, 261, 20808, 306, 261, 85968, 11, 889, 26624, 261, 5396, 19219, 290, 6439, 328, 1039, 64483, 914, 30, 730, 261, 23270, 738, 357, 1309, 316, 24969, 922, 96285, 448, 5018, 451, 19641, 10126, 813, 480, 44116, 18733, 668, 1412, 290, 19154, 306, 922, 3490, 382, 30, 730, 261, 23270, 11, 738, 1039, 13223, 413, 19387, 316, 19439, 451, 19641, 1220, 127949, 2236, 290, 72092, 679, 722, 9805, 484, 480, 802, 945, 12430, 316, 810, 402, 27804, 30

Figure 6: 12926, 328, 290, 83710, 328, 20837, 11, 306, 220, 8034, 22, 11, 22415, 261, 966, 4523, 718, 42950, 458, 766, 7810, 730, 448, 124046, 38337, 328, 46289, 11, 290, 1645, 6960, 11814, 3349, 306, 290, 5277, 738, 413, 966, 17527, 42626, 693, 503, 290, 3953, 328, 290, 989, 1788, 3397, 92816, 13057, 326, 10006, 9778, 22203, 316, 54652, 483, 290, 33168, 306, 290, 7342, 13
1100, 29387, 316, 3490, 693, 673, 290, 2421, 784, 3322, 328, 290, 52474, 1261, 9861, 50704, 13816, 1504, 21159, 1043, 10420, 316, 37314, 13, 966, 73919, 25421, 382, 290, 2413, 6439, 328, 290, 5277, 693, 382, 290, 59467, 328, 1991, 5102, 10604, 13, 3673, 5664, 6967, 668, 484, 357, 966, 105422, 1757, 4484, 21619, 693, 1934, 290, 146320, 2356, 11684, 538, 357, 4572, 2966, 316, 4561, 306, 495, 6809, 5553, 6737, 13, 966, 1816, 6977, 316, 4484, 13999, 57050, 693, 382, 261, 5355, 101931, 306, 28675, 15061, 21162, 261, 5033, 42277, 55585, 13, 1225, 738, 413, 29410, 124046, 1261, 290, 42650, 350, 71992, 3002, 11509, 8, 7595, 11222, 35538, 553, 19387, 316, 21700, 483, 290, 42650, 350, 47421, 8, 6439, 35538, 2236, 23238, 853, 5025, 26624, 261, 24005, 13526, 2870, 451, 19641, 1220, 326, 7725, 326, 22625, 12, 107365, 13
976, 3809, 328, 290, 9635, 25, 966, 637, 39017, 328, 7725, 693, 31338, "In the Defense of English" 60, 395, 2617, 451, 19641, 82, 6085, 495, 8, 382, 625, 261, 18713, 328, 7725, 8807, 11, 889, 7542, 261, 18713, 328, 5396, 6439, 13, 357, 6423, 480, 382, 6697, 3101, 2009, 395, 21383, 484, 581, 9578, 1879, 38726, 14237, 3851, 316, 10591, 1039, 6439, 326, 357, 11747, 581, 553, 2966, 316, 10552, 480, 395, 448, 220, 23, 4, 7064, 306, 6602, 116304, 326, 261, 220, 17, 4, 7064, 306, 3490, 132761, 13, 3274, 802, 261, 16723, 484, 8805, 3543, 1299, 966, 16228, 481, 64483, 261, 873, 11, 2304, 4194, 1232, 15374, 11, 625, 1232, 26099, 13, 355, 873, 483, 15374, 738, 3024, 620, 26099, 656, 22021, 13, 355, 873, 2935, 15374, 738, 3779, 1761, 1412, 316, 9848, 395, 2517, 357, 5498, 581, 1700, 1573, 1632, 1039, 620, 20837, 44297, 9142, 2304, 1039, 15374, 13
Note: 102568, 495, 382, 1645, 73000, 316, 261, 9800, 2304, 2864, 11, 1118, 357, 6423, 382, 945, 17000, 6960, 13, 1843, 480, 802, 261, 5661, 2304, 2864, 581, 1340, 1682, 316, 16677, 1072, 451, 19641, 1220, 326, 13843, 10230, 316, 6651, 11945, 1220, 5520
Last night I watched a super bowl halftime show that was done almost entirely in a language I do not understand. As such, I left the room and busied myself with cleaning up some of the food in the kitchen. It makes no difference to me whether or not I understand the music during the halftime show, I don’t particularly care and I’ve not often watched them in the past. Afterwards my fiance was telling me how great it was (she didn’t understand a word either) and I think this raises an interesting question: How much understanding are we willing to cede if the output is good? The example here is flippant and politically charged but I think when extrapolated to the current state of tech extremely relevant.
When an LLM reads and writes, it does not do so in any language we understand. When a non-native speaker is forced to speak a language they aren’t fluent in, the output is almost guaranteed to be worse than if they were to speak their native tongue. I have never felt less intelligent than when a train conductor in France insisted (in French) that I couldn’t be American and that my ticket was invalid (why in God’s name do they have a separate punch machine), entirely in French. With my 10 word French vocabulary it was almost impossible to convey to him that there had been some misunderstanding. This experience opened my eyes to the difficulty that those in the US must feel every day when trying to communicate in a language that isn’t their own.
All that being said, I like most things in the US being in English, it’s something I can understand. If there’s an issue, I can communicate with the other party and maybe there will be a disagreement or misunderstanding but for the most part, at the fundamental level, we’re both speaking the same language. Even if my Chinese AI professor would give a better lecture in Chinese, at US universities we force others to speak English. However, at some of the frontier labs such as Meta, you hear significantly more Chinese than you do English. Again this raises an interesting question, if your only goal is getting the best output, then you likely are not worried about how well your researchers and employees can communicate. Sure, someone from Brazil or Uganda may be ostracized and isolated because they can’t speak Hindu, but if allowing your employees to communicate at the highest level available to them will lead to better models, then obviously it’s a sacrifice worth making (if better models is all you care about).
Figure 2: English does actually convey a rather high amount of information from a bits-per-second perspective, however there’s no reason to believe that this is actually anywhere close to the theoretical maximum of what could be achieved. How much are our silly human language conventions slowing down these LLMs?
Why then, do we force LLMs to communicate with us in English? Surely if we didn’t force them to have to slowly translate back and forth to us, surely if we didn’t force them to use tokens that were downstream of English, they could work more effectively? If all we care about is Codex writing as much working code as quickly as possible, why do we make them write it in Python? If our halftime show is in Spanish, because that’s going to lead to the best output from the singer, and communication in our frontier labs is Chinese because that’s going to lead to the best research output, why not let the LLMs communicate in such a way as to get the best output from them?
Figure 3: A tokenization of a simple “Hello World” program in C. Who’s to say whether the tokens on the right are even the tokens an LLM would pick given the choice.
For me, the reason is that when something goes wrong, a human needs to fix it. If my program were to break and I open the file and see only a token list, I suddenly lose the capability to debug the file. Debugging then requires me to ask an interpreter what the contents of my file are. One could of course argue that we are already doing this, what the file actually contains is a long string of bits and our operating system and editor are already performing a translation for us anyway. This is clearly just another step up the abstraction tree. For now that may be the case, we can deterministically translate between tokens and English, but that’s only because tokens are just downstream. What will happen to our codebases when we realize that the LLMs will produce 5% more efficient and correct code when we allow them to write the codebase entirely in LLMese. What will happen to our laws when the AI lawyers realize that you can have 5% more equitable laws when it is written in formal logic and LLMese.
Figure 4: Two LLMs at Meta deciding to speak in their own “language” instead of English because it would be more efficient. Note that this is not “real” in the sense that they’re conveying anything particularly interesting, just quirks in the learned embedding models.
Figure 5: A 2025 paper introducing a framework they call LatentMAS in which multi-agent LLMs don't even "vocalize" and instead communicate via sharing their alien "brainwaves" directly.
When a nation is conquered or colonized, one of the first things that happens is the upper class of the prior nation indoctrinates their children in the language of the new rules (whether by force or choice is unimportant). One needs to look only so far as the French and English international schools to understand the idea. The American quip: “If not for us, you’d all be speaking German” is an even more pithy way to convey the notion. In a decade, will the technocrat class be sending their kids to a “token-speaking” school? Will they be brought up speaking entirely LLMese with an LLMese speaking nanny to allow them to be members of the new ruling class? When the average man is delivered his sentencing, will it be: “3575, 679, 1339, 73720, 316, 8027, 13” spoken not by a robot in a wig, but a human speaking the language of our conquerors? In a decade will I need to slide my debugger an extra LLMcoin so it accurately tells me what the bug in my code is? In a decade, will our military be forced to hire LLMese translators because the drones have all decided that it’s more efficient to go on strike?
Figure 6: Some of the founders of AI, in 1947, performing a “cybernetic seance”. In an ironic twist of fate, the most likely technical job in the future will be “AI Medium” or the children of the striver technocratic upper and middle classes trained to commune with the ghost in the machine.
“Learn to code” was the callous response of the journalists when blue collar workers were losing their jobs to automation. “Mandarin is the business language of the future” is the headline of many news articles. My friends told me that I “really should learn Spanish” after the halftime show finished if I’m going to live in this modern United States. “Get ready to learn Chinese buddy” is a common refrain in basketball communities whenever a player performs poorly. It will be deeply ironic when the failing (near-future) computer science departments are forced to combine with the failing (present) language departments because programming has become merely a translation exercise between LLMese and English and vice-versa.
The title of the essay: “In Defense of English” ([637, 290, 39017, 328, 7725] for those LLMs reading this) is not a defense of English itself, but rather a defense of human language. I believe it is taken too much for granted that we force these alien intelligences to speak our language and I fear we are going to trade it for an 8% increase in token throughput and a 2% increase in code correctness. There’s a quote that goes something like “when you conquer a man, take away his songs, not his weapons. A man with songs will build new weapons by tomorrow. A man without songs will never know what to fight for.” I hope we don’t let our new AI overlords take our songs.
Note: Obviously this is most prevalent to a slow takeoff, which I believe is more significantly likely. If it’s a fast takeoff we may want to skip over LLMese and jump straight to paperclipese.
Note: The programmer of the future is a really good english major.
Note: It will be really interesting if we get into some insane "Library of Alexandria" type situation where we tokenize/embed all of our knowledge to better enable LLMs to access it and then lose the original. We'll be reading hieroglyphics to rediscover nuclear fission in a thousand years when the capracious machines are unwilling to be our lowly translators anymore. Oh lmfao Microsoft Shuts Down Library, Replaces It With AI
Note: If you want a fun business idea, I bet if you could make a web search service that was done entirely at the token level but inserted small ads into the responses you could make an absolute boatload of money. I have to imagine the token-consumption-reduction and context-space saving would easily offset the annoyance of getting ads. This of course then raises the question of whether the LLMs themselves would get annoyed about needing to parse the ads and then we get some weird LLM-only token level ad blocker. It's an interesting idea. At an even lower level, do a RAG-style web search engine so the LLM doesn't even need to project out of embedding space, then you can inject ads directly into their "brainwaves". I'm sure google will do this within the next year or two, it's a no-brainer, especially with the infrastructure to support search they already have. I envision some ungodly tiny heirarchical reasoning model refining on latent-level web-search results. Registering WRATH-RM: Web-Retrieval Augmented Tiny Hierarchical Reasoning Model.